Защита данных
Огромный недостаток систем файл-серверных баз данных- незащищенность данных от ошибок, повреждений и разрушения по причине их физической доступности при совместном использовании файлов клиентами и установления над ними прямого контроля со стороны человека. В модели базы данных клиент-сервер приложения клиентов никогда не работают с физическими данными. Когда клиентский запрос изменяет состояние данных, сервер подвергает запрос строгой проверке. Он отвергает запросы, которые не соответствуют внутренним правилам или правилам метаданных. Когда выполняется успешный запрос на запись данных, фактическое изменение состояния базы данных полностью выполняется кодом, находящимся в модуле сервера, а структура диска находится под контролем сервера.
Распределение функций
Модель клиент-сервер позволяет отдельным фрагментам работы системы быть эффективно распределенными между компонентами аппаратуры и программного обеспечения. Сервер базы данных заботится о хранении, управлении и поиске данных, а через хранимые процедуры, триггеры и другие вызываемые процессы он обеспечивает большое количество возможностей обработки данных системы. Процесс клиента является "острием" приложений, транслируя их запросы в структуры коммуникации, которые формируют протоколы для доступа к базам данных и к данным.
Приложения являются динамическим уровнем в этой модели. Они обеспечивают потенциально бесконечное множество интерфейсов, через которые люди, машины и внешние программные процессы взаимодействуют с клиентским процессом. В этой части клиентский модуль представляется приложениям через понятный, предпочтительно стандартизованный, независимый от языка программирования интерфейс прикладного программирования (Application Programming Interface, API).
В некоторых системах приложения могут действовать почти полностью как поставщики информации и приемники ввода, виртуально делегируя все операции манипулирования данными серверу базы данных. Это является идеалом клиент-серверных систем, поскольку локализует задачи, интенсивно использующие центральный процессор, и позволяет приложениям использовать возможности рабочей станции для лучшей реализации интерфейса пользователя.
На другом конце шкалы находятся системы, в которых из-за плохого проектирования или из-за отсутствия функциональной совместимости вся обработка данных виртуально производится на клиентских рабочих станциях. Для таких систем часто бывает характерным плохо выполненный интерфейс пользователя, задержки при синхронизации состояния базы данных и ненадежность взаимодействия с сетью.
Между небесами и адом находятся хорошо выполненные системы баз данных клиент-сервер, которые прекрасно используют возможности обработки на серверах, сохраняя некоторые функции обработки данных на рабочих станциях, когда это оправдано сокращением сетевого трафика или повышением гибкости выполнения задач.
Двухуровневая модель
Рис. 5.1 иллюстрирует классическую двухуровневую модель клиент-сервер. Промежуточный уровень, который может присутствовать или отсутствовать, представляет собой драйвер, такой как ODBC, JDBC, PHP, или компонент доступа к данным, который интегрирован с программным кодом приложения. Возможны и другие уровни на клиентской стороне. Приложения также могут быть написаны с использованием прямого доступа к API без промежуточного уровня.
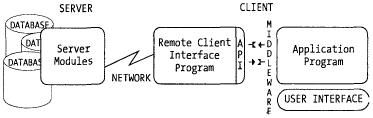
Рис. 5.1. Двухуровневая модель клиент-сервер
Многоуровневая модель
Увеличение возможностей масштабирования и требования большей функциональной совместимости приводят к модели с большим количеством уровней, как показано на рис. 5.2. Клиентский интерфейс перемещается в центр модели; он объединяется с одним или более уровнями сервера приложений. В этом центральном комплексе будут расположены средства промежуточного уровня и сетевые модули. Уровень приложения становится некоторым видом суперклиента базы данных - иногда обслуживая множество серверов баз данных - и сам становится Proxy-сервером (сервером-посредником) для запросов к базам данных от приложений. Он может быть размещен на том же аппаратном оборудовании, что и сервер базы данных, но также может выполняться и на своем оборудовании.
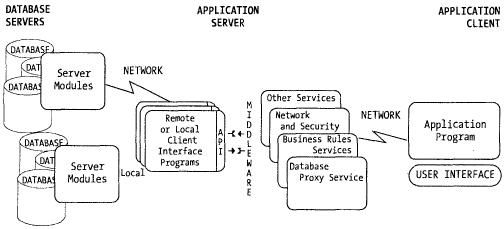
Рис. 5.2. Многоуровневая модель клиент-сервер
Стандартизация
Признанные стандарты функциональной совместимости аппаратного и программного обеспечения, и особенно языка запросов и описания метаданных, являются характерной чертой систем баз данных клиент-сервер. Развитие систем реляционных баз данных и консолидация стандартов SQL более двух десятилетий было и остается неразделимым. Абстрактная природа хорошо спроектированных систем реляционных баз данных вместе с их относительной нейтральностью по поводу выбора языка приложения для "предварительной обработки" гарантируют, что реляционные СУБД продолжают занимать свое место в качестве предпочтительной архитектуры систем клиент-сервер.
Тем не менее это не отменяет другие архитектуры. Хотя в настоящее время объекты систем баз данных продолжают оставаться тесно связанными с языками приложения, объектно-реляционные архитектуры становятся значительным посягательством на реляционные традиции. Самые последние стандарты SQL представляют некоторые положения по стандартизации объектно-реляционных методов и синтаксиса. Когда люди начинают требовать стандарты для технологий, обычно это хороший индикатор того, что технология может быть востребованной в скором времени.
Проектирование систем клиент-сервер
Факт, что системы клиент-сервер должны быть спроектированы для использования в сетях. Для новичков часто бывает потрясением открытие того, что "молниеносно выполняемая" задача, которая работала в приложении под Paradox или Access, занимает весь день после конвертирования в клиент-серверную реляционную СУБД.
"Что-то не так в Firebird, - говорят они. - Это не может быть код моего приложения - потому что я не изменял ничего! Это не может быть результатом моего проектирования базы данных - потому что то же проектирование было безупречным многие годы!" Знаменитые последние слова.
Основа проектирования клиентов для настольных систем резко отличается от проектирования удаленных клиентов в архитектуре клиент-сервер. Обязательный интерфейс просмотра в настольных системах, где отображаются "200 000 записей за один раз", создал крупную отрасль RAD разработки компонентов DBGrid, связанных с данными (data-aware components). Разработчику никогда не нужно думать о том, какое количество человек в состоянии просмотреть 200 000 записей в день, пусть только одним взглядом!
Эти компоненты в RAD, которые выполнили такую замечательную работу по представлению неограниченного объема данных в настольных системах в небольших контейнерах для произвольного просмотра, не являются дружественным интерфейсом для удаленных клиентов. Если ранее характерная клиентская операция цикла ("начать с первой записи и для каждой записи повторить"), казалась идеальной для обработки данных, которые размещались в памяти как локальные таблицы, то теперь удаленные пользователи клиентских компьютеров требуют принести им голову разработчиков на блюде.
Действительно, общим является то, что на проектирование базы данных наиболее сильно влияет восприятие клиентского интерфейса - "Мне нужна таблица, похожая на эту электронную таблицу!"- а не элегантная мудрость абстрактной модели данных.
Когда интерфейс физически отделен от данных через уровень изоляции транзакции и через сеть с загруженным каналом, то требуется больше размышления. Для выполнения миграции с настольной системы требуется много больше, чем просто преобразования данных. Максимальное преимущество критического пересмотра проектирования для пользователей, целостности базы данных и эффективности выполнения будет весьма оправданной работой.
Абстракция хранимых данных
Даже в современных системах клиент-сервер можно найти слишком много плохо выполняющихся, подверженных ошибкам приложений, которые были "спроектированы" с использованием отчетов и электронных таблиц в качестве основы для проектирования базы данных и пользовательского интерфейса. В итоге существует слишком много общего при переходе от настольных баз данных к Firebird с множеством следующих недружественных для платформ клиент-сервер "возможностей".
* Распространенная избыточность структур, которая перешла от электронных таблиц к базам данных с одними и теми же элементами данных, повторяющихся во многих таблицах.
* Иерархические структуры первичных ключей (нужны во многих настольных системах баз данных для реализации зависимостей), что нарушает уточненную модель ограничений внешнего ключа в зрелых реляционных базах данных.
* Большие составные символьные ключи, составленные из столбцов реальных данных.
* Недостатки нормализации, приводящие к большому количеству записей содержащих много повторяющихся групп и редко требуемой информации.
* Большое количество частично совпадающих друг с другом индексов, не являющихся необходимыми.