Библиотечные функции
Проблема использования низкоуровневых системных вызовов непосредственно для ввода и вывода заключается в том, что они могут быть очень неэффективны. Почему? Ответ может быть следующим.
□ При выполнении системных вызовов существуют эксплуатационные издержки. Поэтому системные вызовы требуют больше затрат по сравнению с библиотечными функциями, т.к. ОС Linux вынуждена переключаться с выполнения вашего программного кода на собственный код ядра и затем возвращаться к выполнению вашей программы. Было бы неплохо стараться свести к минимуму применение системных вызовов в программе и заставлять каждый такой вызов выполнять максимально возможный объем работы, например, считывать и записывать за один раз большие объемы данных, а не одиночные символы.
□ У оборудования есть ограничения, накладываемые на размер блока данных, которые могут быть считаны или записаны в любой конкретный момент времени. У ленточных накопителей, например, часто есть размер блока для записи, скажем 10 Кбайт, поэтому, если вы попытаетесь записать количество информации, не кратное 10 Кбайт, накопитель переместит ленту к следующему блоку в 10 Кбайт, оставив на ленте пустоты.
Для формирования высокоуровневого интерфейса для устройств и дисковых файлов дистрибутив Linux (и UNIX) предоставляет ряд стандартных библиотек. Они представляют собой коллекции функций, которые вы можете включать в свои программы для решения подобных проблем. Хорошим примером может послужить стандартная библиотека ввода/вывода, обеспечивающая буферизованный вывод. Вы сможете эффективно записывать блоки данных разных размеров, применяя библиотечные функции, которые будут выполнять низкоуровневые системные вызовы, снабжая их полными блоками, как только данные станут доступны. Это существенно снижает издержки системных вызовов.
Библиотечные функции, как правило, описываются в разделе 3 интерактивного справочного руководства и часто снабжаются стандартным файлом директивы include, связанным с ними, например, файл stdio.h для стандартной библиотеки ввода/вывода.
Для обобщения материала последних нескольких разделов на рис. 3.2 приведена схема системы Linux, на которой показано, где расположены различные функции работы с файлами относительно пользователя, драйверов устройств, ядра системы и оборудования.
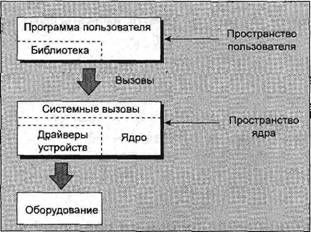
Рис. 3.2
Низкоуровневый доступ к файлам
У каждой выполняющейся программы, называемой процессом, есть ряд связанных с ней дескрипторов файлов. Существуют короткие целые (small integer) числа, которые можно использовать для обращения к открытым файлам и устройствам. Количество дескрипторов зависит от конфигурации системы. Когда программа запускается, у нее обычно уже открыты три подобных дескриптора. К ним относятся следующие:
□ 0 - стандартный ввод;
□ 1 - стандартный вывод;
□ 2 - стандартный поток ошибок.
Вы можете связать с файлами и устройствами другие дескрипторы файлов, используя системный вызов open, который уже обсуждался вкратце. Дескрипторы файлов, открытые автоматически, уже позволяют вам создавать простые программы с помощью вызова write.
write
Системный вызов write предназначен для записи из buf первых nbytes байтов в файл, ассоциированный с дескриптором fildes. Он возвращает количество реально записанных байтов, которое может быть меньше nbytes, если в дескрипторе файла обнаружена ошибка или дескриптор файла, расположенный на более низком уровне драйвера устройства, чувствителен к размеру блока. Если функция возвращает 0, это означает, что ничего не записано; если она возвращает -1, в системном вызове write возникла ошибка, которая описывается в глобальной переменной errno,
Далее приведена синтаксическая запись.
#include <unistd.h>
size_t write(int fildes, const void *buf, size_t nbytes);
Благодаря полученным знаниям вы можете написать свою первую программу, simple_write.c:
#include <unistd.h>
#include <stdlib.h>
int main() {
if ((write(1, "Here is some data\n", 18)) != 18)
write(2, "A write error has occurred on file descriptor 1\n", 46);
exit(0);
}
Эта программа просто помещает сообщение в стандартный вывод. Когда она завершается, все открытые дескрипторы файлов автоматически закрываются, и вам не нужно закрывать их явно. Но в случае буферизованного вывода это не так.
$ ./simple_write
Here is some data
$
И еще одно маленькое замечание: вызов write может сообщить о том, что записал меньше байтов, чем вы просили. Это не обязательно ошибка. В ваших программах вам придется для выявления ошибок проверить переменную errno и еще раз вызвать write для записи оставшихся данных.
read
Системный вызов read считывает до nbytes байтов данных из файла, ассоциированного с дескриптором файла fildes, и помещает их в область данных buf. Он возвращает количество действительно прочитанных байтов, которое может быть меньше требуемого количества. Если вызов read возвращает 0, ему нечего считывать; он достиг конца файла. Ошибка при вызове заставляет его вернуть -1.
#include <unistd.h>
size_t read(int fildes, void *buf, size_t nbytes);
Программа simple_read.c копирует первые 128 байтов стандартного ввода в стандартный вывод. Она копирует все вводимые данные, если их меньше 128 байтов.
#include <unistd.h>
#include <stdlib.h>
int main() {
char buffer[128];
int nread;
nread = read(0, buffer, 128);
if (nread == -1)
write(2, "A read error has occurred\n", 26);
if ((write(1, buffer, nread)) != nread)
write(2, "A write error has occurred\n", 27);
exit(0);
}
Если вы выполните программу, то получите следующий результат:
$ echo hello there | ./simple_read
hello there
$ ./simple_read < draft1.txt
Files
In this chapter we will be looking at files and directories and how to
manipulate them. We will learn how to create files, $
Первое выполнение программы с помощью команды echo формирует некоторый ввод программы, который по каналу передается в вашу программу. Во втором выполнении вы перенаправляете ввод из файла draft1.txt. В этом случае вы видите первую часть указанного файла, появляющуюся в стандартном выводе.
Примечание
Обратите внимание на то, что знак подсказки или приглашения командной оболочки появляется в конце последней строки вывода, поскольку в этом примере 128 байтов не формируют целое число строк.
open
Для создания дескриптора нового файла вы должны применить системный вызов open.
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int open(const char *path, int oflags);
int open(const char *path, int oflags, mode_t mode);
Примечание
Строго говоря, для использования вызова open вы не должны включать файлы sys/types.h и sys/stat.h в системах, удовлетворяющих стандартам POSIX, но они могут понадобиться в некоторых системах UNIX.