Всего за 133 руб. Купить полную версию
Стоит обратить внимание, что, так как данный МП-автомат строит правосторонний вывод, в цепочке вывода на каждом шаге правило всегда применяется к крайнему правому нетерминальному символу в цепочке.
Дерево синтаксического разбора, соответствующее данной входной цепочке, приведено на рис. 3.2.
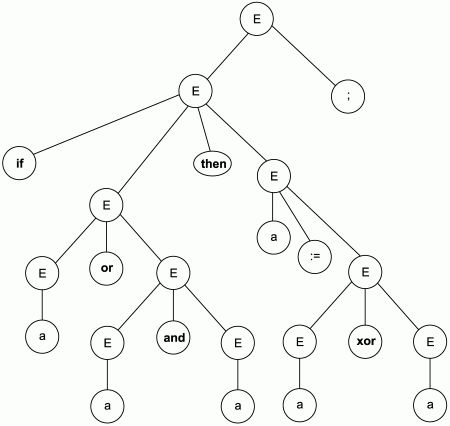
Рис. 3.2. Дерево синтаксического разбора входной цепочки "if a or a and a then а:= а хог а;".
Пример 2
Возьмем входную цепочку "if {a or b then а:= 25;".
После выполнения лексического анализа, если все лексемы типа "идентификатор" и "константа" обозначить как "а", получим цепочку: "if (a or a then а:= а".
Рассмотрим процесс синтаксического анализа этой входной цепочки:
{if (a or a then a := a;⊥к|⊥н |λ} ÷ п
{(a or a then a := a;⊥к|⊥н if|λ} ÷ п
{a or a then a := a;⊥к|⊥н if(|λ} ÷ п
{or a then a := a;⊥к|⊥н if(a|λ} ÷ с
{or a then a := a;⊥к|⊥н if(E|12} ÷ п
{a then a := a;⊥к|⊥н if(E or|12} ÷ п
{then a := a;⊥к|⊥н if(E or a|12} ÷ с
{then a := a;⊥к|⊥н if(E or E|12 12} ÷ с
{then a := a;⊥к|⊥н if(E|12 12 7} – нет отношения предшествования между лексемами "(" и "then", разбор закончен, МП-автомат не перешел в конечную конфигурацию, цепочка не принята (выдается сообщение об ошибке).
Реализация синтаксического распознавателя
Разбиение на модули
В лабораторной работе № 3, так же, как и в лабораторной работе № 2, модули, реализующие синтаксический анализатор разделены на две группы:
• модули, программный код которых не зависит от входного языка;
• модули, программный код которых зависит от входного языка.
В первую группу входят модули:
• SyntSymb – описывает структуры данных для синтаксического анализа и реализует алгоритм "сдвиг-свертка" для грамматик операторного предшествования;
• FormLab3 – описывает интерфейс с пользователем.
Во вторую группу входит один модуль:
• SyntRulе – содержит описания матрицы операторного предшествования и правил исходной грамматики.
Такое разбиение на модули позволяет использовать те же самые структуры данных для организации синтаксического распознавателя при изменении входного языка.
Кроме этих модулей для реализации лабораторной работы № 3 используются программные модули TblElem и FncTree, позволяющие работать с комбинированной таблицей идентификаторов, которые были созданы при выполнении лабораторной работы № 1, а также модули LexType, LexElem, и LexAuto, которые обеспечивают работу лексического распознавателя (эти модули были созданы при выполнении лабораторной работы № 2).
Кратко опишем содержание программных модулей, используемых для организации синтаксического анализатора.
Модуль описания матрицы предшествования и правил грамматики
Модуль SyntRulе содержит структуры данных, которые описывают матрицу операторного предшествования и правила остовной грамматики.
Матрица операторного предшествования (GramMatrix) описана как двумерный массив, каждой строке и каждому столбцу которого соответствует лексема (тип TLexType). Важно, чтобы данные в строках и столбцах матрицы были заполнены в том же порядке, в каком перечислены типы лексем в описании TLexType в модуле LexType. В каждой клетке матрицы находится символ, обозначающий тип отношения предшествования:
• < – для отношения "<." ("предшествует");
• > – для отношения ".>" ("следует");
• = – для отношения "=." ("составляет основу");
• – для пустых клеток матрицы (когда отношение операторного предшествования между двумя символами отсутствует).
Кроме матрицы операторного предшествования и правил грамматики в модуле SyntRulе описана функция корректировки отношений предшествования CorrectRul е, которая позволяет расширять возможности грамматики операторного предшествования. В данной лабораторной работе эта функция не используется (о технике ее использования можно узнать далее из описания примера выполнения курсовой работы).
В целом описанная в модуле SyntRulе матрица операторного предшествования GramMatrix полностью соответствует построенной матрице операторного предшествования (см. табл. 3.8). Отличие заключается в том, что, поскольку терминальному символу a в грамматике G могут соответствовать два типа лексем входного языка (переменные и константы), в матрице GramMatrix строка и столбец, соответствующие символу a в табл. 3.8, продублированы.
Таким образом, построенный на основе матрицы предшествования из табл. 3.8 синтаксический анализатор не различает константы и переменные. Это соответствует синтаксису заданного входного языка. Для этого языка проводить различие между переменными и константами необходимо только в одном случае: при анализе оператора присваивания (присваивать значение константе нельзя). Для того чтобы компилятор находил такого рода ошибки, возможны два варианта:
1. Изменить синтаксис входного языка (грамматику G) так, чтобы константы и переменные различались в правилах грамматики, и перестроить синтаксический анализатор.
2. Обрабатывать присваивание значений константам на этапе семантического анализа.
В данном случае выбран второй вариант, который реализован в лабораторной работе № 4 (где рассматриваются генерация кода и подготовка к генерации кода). Позже, при разработке компилятора для выполнения курсовой работы, рассмотрен первый вариант (см. главу, посвященную выполнению курсовой работы). Каждый из рассмотренных вариантов имеет свои преимущества и недостатки. В общем случае выбор того, на каком этапе компиляции будет обнаружена та или иная ошибка, зависит от разработчика компилятора.
Правила остовной грамматики G' описаны в виде массива строк GramRules. Каждому правилу в этом массиве соответствует строка, по написанию совпадающая с правой частью правила (пробелы игнорируются). Правила пронумерованы в порядке слева направо и сверху вниз – так, как они были пронумерованы в остовной грамматике G. Для поиска подходящего правила используется метод простого перебора – так как правил мало (всего 13), в данном случае этот метод вполне удовлетворителен.
Кроме двух упомянутых структур данных (GramMatrix и GramRules) в модуле SyntRulе описана также функция MakeSymbolStr, возвращающая наименование нетерминального символа в правилах остовной грамматики. В грамматике G во всех правилах символ обозначен Е, поэтому функция MakeSymbolStr всегда возвращает 'Е' как результат своего выполнения. Но тем не менее эта функция не бессмысленна, так как могут быть другие варианты остовных грамматик.