Всего за 133 руб. Купить полную версию
• Расскажите, как работает алгоритм "перенос-свертка" в общем случае (с возвратами).
• Как работает алгоритм "перенос-свертка" без возвратов (объясните на своем примере)?
Варианты заданий
Варианты исходных грамматик
Далее приведены варианты грамматик. Во всех вариантах символ S является начальным символом грамматики; S, F, T и Е обозначают нетерминальные символы.
Терминальные символы выделены жирным шрифтом. Вместо символа а должны подставляться лексемы.
1. S → a:= F;
F → F+T |Т
Т → Т·Е | TIE | Е
Е → (F) | – (F) | а
2. S → a:= F;
F → F or Т | F хог T | T
T → Т and E | Е
Е → (F) | not (F) | a
3. S → F;
F → if E then T else F| if E then F| a:= a
T → if E then T else T | a:= a
E → a<a | a>a | a=a
4. S → F;
F → for (T) do F | a:= a
T → F;E;F |;E;F | F;E; |;E;
E → a<a I a>a I a=a
Исходные грамматики и типы допустимых лексем
Ниже в табл. 3.1 приведены номера заданий. Для каждого задания указана соответствующая ему грамматика и типы допустимых лексем.
Таблица 3.1. Номера заданий для выполнения лабораторной работы

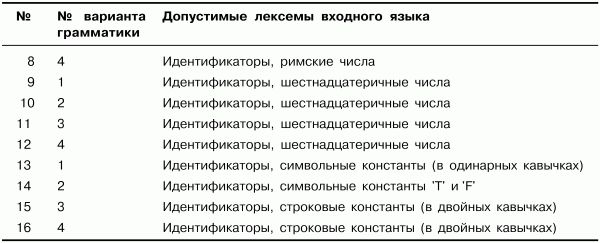
Примечание.
• Римскими числами считать последовательности больших латинских букв X, V и I.
• Шестнадцатеричными числами считать последовательность цифр и символов "а", "Ь", "с", "d", "е" и "f", начинающуюся с цифры (например: 89, 45ас9, 0abc4).
• Для выполнения работы рекомендуется использовать лексический анализатор, построенный в ходе выполнения лабораторной работы № 2.
Пример выполнения работы
Задание для примера
Для выполнения лабораторной работы возьмем тот же самый язык, который был использован для выполнения лабораторной работы № 2.
Этот язык может быть задан, например, с помощью следующей КС-грамматики
G({if,then,else,a,=,or,xor,and,(,),},{S,F,E,D,C},P,S) с правилами P:
S → F;
F → if E then T else F | if E then F | a:= E
T → if E then T else T | a:= E
E → E or D | E xor D | D
D → D and C | C
C → a | (E)
Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
Как было уже сказано ранее, выбранный в качестве примера язык не совпадает ни с одним из предложенных выше вариантов и, кроме этого, служит хорошей иллюстрацией основных особенностей построения синтаксического распознавателя, присущих различным вариантам.
Построение матрицы операторного предшествования
Построение множеств крайних правых и крайних левых символов
Построение множеств крайних левых и крайних правых символов выполним согласно описанному ранее алгоритму.
На первом шаге возьмем все крайние левые и крайние правые символы из правил грамматики G. Получим множества, представленные в табл. 3.2.
Таблица 3.2. Множества крайних левых и крайних правых символов. Шаг 1
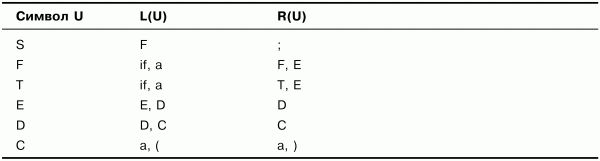
Из табл. 3.2 видно, что множества L(U) для символов S, Е, D, а также множества R(U) для символов F, Т, Е, D содержат другие нетерминальные символы, а потому должны быть дополнены. Например, L(S) должно быть дополнено L(F), так как символ F входит в L(S): F е L(S), а R(F) должно быть дополнено R(E), так как символ Е входит в R(F): Е е R(F).
Выполним необходимые дополнения и получим множества, представленные в табл. 3.3.
Таблица 3.3. Множества крайних левых и крайних правых символов. Шаг 2
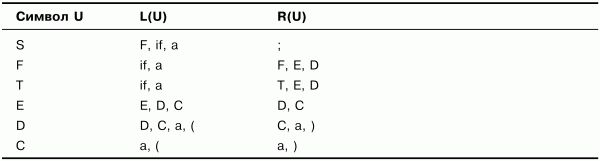
Практически все множества в табл. 3.3 изменились по сравнению с табл. 3.2 (кроме множеств для символа С), а значит, построение не закончено. Продолжим дополнять множества. Получим множества, представленные в табл. 3.4.
В табл. 3.4 по сравнению с табл. 3.3 изменились множества для символов F, Г и Е – построение не закончено. Продолжим дополнять множества. Получим множества, представленные в табл. 3.5.
Таблица 3.4. Множества крайних левых и крайних правых символов. Шаг 3
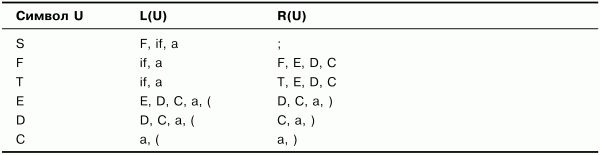
Таблица 3.5. Множества крайних левых и крайних правых символов. Шаг 4 (результат)
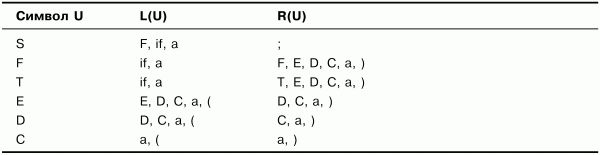
В табл. 3.5 по сравнению с табл. 3.4 изменились только множества R(U) для символов F иT– построение не закончено. Продолжим дополнять множества. Но если выполнить еще один шаг (шаг 5), то можно убедиться, что множества уже больше не изменятся (чтобы не создавать еще одну лишнюю таблицу, этот шаг здесь выполнять не будем). Таким образом, множества, представленные в табл. 3.5, являются результатом построения множеств крайних левых и крайних правых символов грамматики G.
Построение множеств крайних правых и крайних левых терминальных символов
Построение множеств крайних левых и крайних правых терминальных символов также выполним согласно описанному выше алгоритму.
На первом шаге возьмем все крайние левые и крайние правые терминальные символы из правил грамматики G. Получим множества, представленные в табл. 3.6.
Таблица 3.6. Множества крайних левых и крайних правых терминальных символов. Шаг 1

Дополним множества, представленные в табл. 3.6, на основании ранее построенных множеств крайних левых и крайних правых символов, представленных в табл. 3.5. Например, Lt(Е) должно быть дополнено Lt(D) и Lt(C), так как символы D и C входят в L(E): D, С e L(E), а Rt(F) должно быть дополнено Rt(E), Rt(D) и Rt(C), так как символы E, D и С входят в R(F): E, D, С е R(F).
Получим итоговые множества крайних левых и крайних правых терминальных символов, которые представлены в табл. 3.7.
Таблица 3.7. Множества крайних левых и крайних правых терминальных символов. Результат

Теперь все готово для заполнения матрицы операторного предшествования.