Всего за 133 руб. Купить полную версию
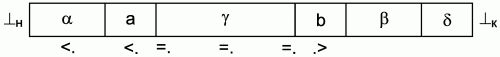
Рис. 3.1. Отношения между символами входной цепочки в грамматике предшествования.
Таким образом, установление непротиворечивых отношений предшествования между символами грамматики в комплексе с несовпадающими правыми частями различных правил дает ответы на все вопросы, которые надо решить для организации работы алгоритма "сдвиг-свертка" без возвратов.
На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми (левыми) символами, столбцы – вторыми (правыми) символами отношений предшествования. В клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования.
Существует несколько видов грамматик предшествования. Они различаются по тому, какие отношения предшествования в них определены и между какими типами символов (терминальными или нетерминальными) могут быть установлены эти отношения. Кроме того, возможны незначительные модификации функционирования самого алгоритма "сдвиг-свертка" в распознавателях для таких грамматик (в основном на этапе выбора правила для выполнения свертки, когда возможны неоднозначности) [1].
Выделяют следующие виды грамматик предшествования:
• простого предшествования;
• расширенного предшествования;
• слабого предшествования;
• смешанной стратегии предшествования;
• операторного предшествования.
Далее будут рассмотрены ограничения на структуру правил и алгоритмы разбора для грамматик операторного предшествования.
Матрицу операторного предшествования КС-грамматики можно построить, опираясь непосредственно на определения отношений предшествования [1, 3, 7], но проще и удобнее воспользоваться двумя дополнительными типами множеств – множествами крайних левых и крайних правых символов, а также множествами крайних левых терминальных и крайних правых терминальных символов для всех нетерминальных символов грамматики.
Если имеется КС-грамматика
![]()
то множества крайних левых и крайних правых символов определяются следующим образом:
![]()
– множество крайних левых символов относительно нетерминального символа U;
![]()
– множество крайних правых символов относительно нетерминального символа U,
где U – заданный нетерминальный символ
![]()
T – любой символ грамматики
![]()
а z – произвольная цепочка символов (
![]()
цепочка z может быть и пустой цепочкой).
Множества крайних левых и крайних правых терминальных символов определяются следующим образом:
![]()
– множество крайних левых терминальных символов относительно нетерминального символа U;
![]()
– множество крайних правых терминальных символов относительно нетерминального символа U,
где t – терминальный символ
![]()
U и С – нетерминальные символы (U,
![]()
а z – произвольная цепочка символов (
![]()
цепочка z может быть и пустой цепочкой).
Множества L(U) и R(U) могут быть построены для каждого нетерминального символа
![]()
по очень простому алгоритму:
1. Для каждого нетерминального символа U ищем все правила, содержащие U в левой части. Во множество L(U) включаем самый левый символ из правой части правил, а во множество R(U) – самый правый символ из правой части (то есть во множество L(U) записываем все символы, с которых начинаются правила для символа U, а во множество R(U) – символы, которыми эти правила заканчиваются). Если в правой части правила для символа U имеется только один символ, то он должен быть записан в оба множества – L(U) и R(U).
2. Для каждого нетерминального символа U выполняем следующее преобразование: если множество L(U) содержит нетерминальные символы грамматики [U', U', …, то его надо дополнить символами, входящими в соответствующие множества L(U'), L(U')… и не входящими в L(U). Ту же операцию надо выполнить для R(U). Фактически, если какой-то символ U' входит в одно из множеств для символа U, то надо объединить множества для U' и U, а результат записать во множество для символа U.
3. Если на предыдущем шаге хотя бы одно множество L(U) или R(U) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе – построение закончено.
Для нахождения множеств Lt(U) и Rt(U) используется следующий алгоритм:
1. Для каждого нетерминального символа грамматики U строятся множества L(U) и R(U).
2. Для каждого нетерминального символа грамматики U ищутся правила вида U → tz и U → Ctz, где
![]()
терминальные символы t включаются во множество Lt(U). Аналогично для множества Rt(U) ищутся правила вида U → zt и U → ztC (то есть во множество Lt(U) записываются все крайние слева терминальные символы из правых частей правил для символа U, а во множество Rt(U) – все крайние справа терминальные символы этих правил). Не исключено, что один и тот же терминальный символ будет записан в оба множества – Lt(U) и Rt(U).
3. Просматривается множество L(U), в которое входят символы U', U' … Множество Lt(U) дополняется терминальными символами, входящими в Lt(U'), Lt(U')… и не входящими в Lt(U). Аналогичная операция выполняется и для множества Rt(U) на основе множества R(U).
Для практического использования матрицу предшествования дополняют терминальными символами
![]()
и
![]()
(начало и конец цепочки). Для них определены следующие отношения предшествования:
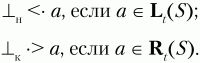
Имея построенные множества Lt(U) и Rt(U), заполнение матрицы операторного предшествования для КС-грамматики G(VT,VN,P,S) можно выполнить по следующему алгоритму:
1. Берем первый символ из множества терминальных символов грамматики VT:
![]()
Будем считать этот символ текущим терминальным символом.
2. Во всем множестве правил Р ищем правила вида C → xaiby или C → xaiUbjy, где аi – текущий терминальный символ, Ьj – произвольный терминальный символ
![]()
U и С – произвольные нетерминальные символы
![]()
а х и у – произвольные цепочки символов, возможно пустые