Всего за 88 руб. Купить полную версию
• У (уточнение сведений о субъекте) – данные о менеджерах фирмы (фамилия, имя, отчество и адрес);
• Р (реквизит-основание) – цена прибора.
Предположим, пользователя в первую очередь интересует не только цена, но и вес прибора. Этот параметр можно выделить из общего массива "характеристика" и придать ему статус еще одного реквизита-основания. Тогда приведенная выше фраза-описание будет содержать две однородные фразы с параллельными реквизитами-основаниями – цена и вес.
В рассмотренном примере структура информации достаточно проста, и нужные словари могут быть сформированы практически сразу, на первом этапе проектирования. Создавая их и уточняя перечень основных реквизитов-признаков, руководствуйтесь следующим критерием: часто ли у пользователя будет необходимость запрашивать информацию по данному признаку. Если да, то имеет смысл выделить его как отдельный реквизит и сформировать соответствующий словарь. Такой признак называется ключевым значением, или дескриптором. В базе данных ему лучше выделить отдельный файл или поле в файле; этим вы существенно облегчите работу будущему пользователю. Конечно, если какой-либо признак "спрятан" в общем тексте, по нему тоже можно сделать запрос, но сформировать последний в этом случае сложнее.
В нашем примере можно сразу выделить те признаки, по которым следует ожидать частого обращения к базе данных:
• название прибора;
• название фирмы, производящей прибор;
• страна, в которой находится фирма;
• адрес фирмы;
• адрес филиала или дочерней фирмы;
• данные о менеджерах фирмы – фамилия, имя, отчество и адрес;
• номер модели;
• год выпуска прибора;
• номер прибора по каталогу;
• цена прибора;
• функциональное назначение прибора;
• вес прибора;
• категория прибора (переносной, портативный и т. п.);
• характеристика прибора.
Параметры, которые для пользователя второстепенны, остаются в общем тексте раздела.
Возьмем пример посложнее, который представлен в разделе "Необходимость структуризации". Здесь описание включает не одну, а несколько фраз, и анализ, подобный предыдущему, надо провести отдельно для каждой из них. В результате мы получим следующий набор признаков:
• П (показатели) – "выявлено", "выдано", "сжигание" и др.;
• О1 (объект) – источники загрязнения (нефтеналивные цистерны);
• О2 (объект) – загрязняющие вещества (нефть);
• О3 (объект) – объекты загрязнения (рельеф местности);
• О4 (объект) – документы (предписание о ликвидации последствий аварии);
• У1 (уточнение места действия 1) – железнодорожные станции (Ангасолка);
• У2 (уточнение места действия 2) – железные дороги (Восточно-Сибирская);
• У3 (обстоятельство действия 1) – под контролем комиссии;
• П (примечания) – как уже говорилось, в этих полях должны содержаться данные – уточнения, специфичные для конкретных сообщений.
Таким образом, по мере накопления новых сообщений будут появляться и новые реквизиты, а количество параметров, указанных в скобках, тоже будет расти.
Проектирование логической структуры базы данных
Итак, мы определили состав дескрипторов, то есть ключевых полей для поиска, по которым чаще всего (по нашему прогнозу) будут формироваться запросы к базе данных. Теперь начнем разработку логической структуры БД. Под логической структурой понимается та совокупность файлов, содержащихся в них полей и связей между файлами, которую "видит" пользовательская программа, обрабатывающая базу данных.
Распределение полей по файлам
В предыдущем разделе мы постарались объяснить, почему и как необходимо выделять дескрипторные поля, по которым ожидаются запросы со стороны пользователя. Мы исходили из того, что каждому такому полю должен соответствовать словарь. Если вы в этом еще сомневаетесь, вспомните, что между элементами информации существуют различные типы отношений: "один-к-одному", "один-ко-многим", "многие-ко-многим". Очевидно, когда между какими-то элементами информации (полями) существует отношение "один-к-одному", они жестко и однозначно взаимосвязаны. В таком случае достаточно иметь один словарь на всю эту группу. Но тогда она должна находиться в одном файле, потому что иначе отношение "один-к-одному" не будет реализовано без применения каких-либо дополнительных средств. Как видите, логика довольно проста. Теперь у нас есть критерий для распределения полей по файлам: в одном файле следует размещать те поля, которые связаны между собой отношением "один-к-одному". Файлы, объединяющие такие группы полей, будут находиться друг с другом в отношении "один-ко-многим" и составят иерархическую структуру. Отметим, что файлы, находящиеся в отношениях типа "многие-ко-многим", не должны быть непосредственно взаимосвязанными. Обобщим сказанное в табл. 2.1.
В этой таблице символы Х и и обозначают соответственно стороны "многие" и "один" в отношениях между реквизитами.
Таблица 2.1
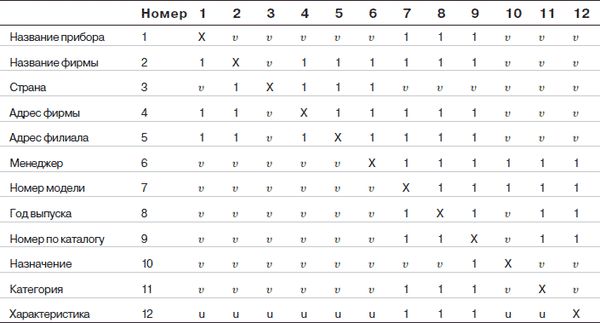
Файлы и связи между ними
Из табл. 2.1 видно: чтобы формировать файлы, следует сгруппировать в них поля, представляющие реквизиты-признаки, находящиеся друг с другом, как сказано выше, в отношении "один-к-одному". Таким образом, будут созданы следующие файлы:
• Страны (содержит поле Название страны);
• Приборы (содержит поля Номер модели, Категория, Год выпуска, Характеристика, Номер по каталогу, Цена, Вес);
• Фирмы (содержит поля Название фирмы, Адрес фирмы, Адрес филиала);
• Менеджер (содержит поле Данные о менеджере);
• Назначение (содержит поле Назначение прибора);
• Типы приборов (содержит поле Название прибора).
Мы перечислили здесь основные – так сказать, "титульные" – поля, составляющие каркас конкретной таблицы. В нее могут также входить вспомогательные поля: Примечания, Адрес и др. Соединив эти файлы связями типа "один-ко-многим", мы получим логическую структуру базы данных, условный вид которой показан на рис. 2.1. О практической реализации таких связей речь пойдет в конце следующей главы.

Рис. 2.1
Резюме
1. Безусловный прогресс, достигнутый в развитии программных средств СУБД и расширении их функциональных возможностей, не устранил проблему обоснованности выбора структур баз данных – от продуманности этих структур во многом зависит эффективность работы с базами данных (БД).
2. Основным элементом фактографической информации является показатель. Он, в свою очередь, состоит из множества реквизитов-признаков и единственного реквизита-основания.
3. Для того чтобы формировать по единым правилам разнообразные пользовательские запросы к БД и получать на них ответы, перед проектированием конкретных баз данных необходимо провести структуризацию информации.
4. В настоящей главе предлагается и иллюстрируется на конкретном примере технология такой структуризации и – на ее основе – последующего проектирования логической структуры БД.
Глава 3 Создание таблиц новой базы данных
Как уже было сказано в главе 2, разработка новой базы данных "Контрольно-измерительные приборы" производится в программной среде Access 2002.
Формирование БД в Access состоит из ряда последовательных этапов, описываемых ниже. Первый этап этого процесса – создание таблиц. Таблицы в Access являются теми первичными, исходными файлами, на основе которых в дальнейшем строится все здание базы данных. Access 2002, как и предыдущие версии, предоставляет пользователю несколько разных вариантов построения таблиц, а также возможность применения дополнительных аналитических табличных структур.
Порядок создания всех таблиц одинаков и не зависит от их названия и конкретного содержания. Мы рассмотрим этот процесс на примере таблицы Страны.
Варианты создания таблиц
Формирование таблицы начинается с того, что вы открываете окно базы данных и в нем выбираете пункт Таблицы в разделе Объекты – рис. 3.1.
Рис. 3.1
Дальше следует щелкнуть по кнопке
![]()
на панели окна БД. В диалоговом окне Новая таблица, показанном на рис. 3.2, представлены все возможные параметры создания таблицы:

Рис. 3.2
• Режим таблицы;
• Конструктор;
• Мастер таблиц;
• Импорт таблиц;
• Связь с таблицами.
Последние два варианта создания таблиц – импорт таблиц и связь с таблицами – рассматриваются в том разделе главы 7, который посвящен объединению разнородных баз данных.